Adding Memory to GPT Models
 Distant Memories by Stable Diffusion.
Distant Memories by Stable Diffusion.
In this blog post, I explore adding memory to GPT models through prompt augmentation. I document three different methods and explain how to implement them in Python. I also demonstrate how to build a mini version of ChatGPT with those techniques.
Introduction
Large language models (LLMs), and more specifically GPT, are powerful tools that are already transforming various industries. One example of applied GPT is ChatGPT, which in the past few months has taken the world by storm. Since the first time I’ve interacted with it, I’ve been wondering how it remembers what was said previously in the conversation. The original writeup by OpenAI only covers the training methods but doesn’t go into detail about how it’s able to retain memory of the ongoing dialog. The only official explanation provided by OpenAI is sparse on details:
While ChatGPT is able to remember what the user has said earlier in the conversation, there is a limit to how much information it can retain. The model is able to reference up to approximately 3000 words (or 4000 tokens) from the current conversation—any information beyond that is not stored.
This leaves us to speculate as to how OpenAI actually got it to work. It’s probably safe to assume that it uses an internal version of the Text Completion API and a zero-shot learning technique of adding previous questions and answers to the prompt or, in other words, “memorizing” them.
After some research and experimentation, I discovered a handful of ways to memorize the conversation, each with its own pros and cons. Before I dive into them, let me introduce some terminology that I’ll use throughout this writeup:
Terminology
Workflow is a directed acyclic graph (DAG) of steps with branching memory. In this post I will only look at linear workflows that form chains of steps.
Step is an input/output pair where input is a prompt value and output is an LLM output.
Memory fidelity is a measure of how many preceding steps are added to the prompt in their original form, uncompressed. I don’t introduce a formal text compression metric in this writeup, but it could be interesting to look at BLEU, ROUGE, or METEOR scores for memory fidelity metrics in the future.
Prompt stack is the structure of a prompt sent to the model. It can have different sections such as rules, summary, and workflow steps.
Memory Types
1. Unbounded Memory
This type of memory simply passes all previous steps into the prompt. This brute force approach is limited by the amount of prompt tokens available in the model. It could be useful for short workflows.
2. Buffer Memory
One way to improve the previous type of memory is to only keep the last N steps of the workflow in memory, so that the prompt doesn’t exceed the token limit. This approach works great for shorter conversations but completely forgets everything before the last N steps of the workflow. This approach is likely the one used by ChatGPT where they dynamically adjust the buffer size based on available tokens.
Here is a high-level diagram of how unbounded and buffer memory types are implemented in GalaxyBrain, my experimental Python library for AI workflows:
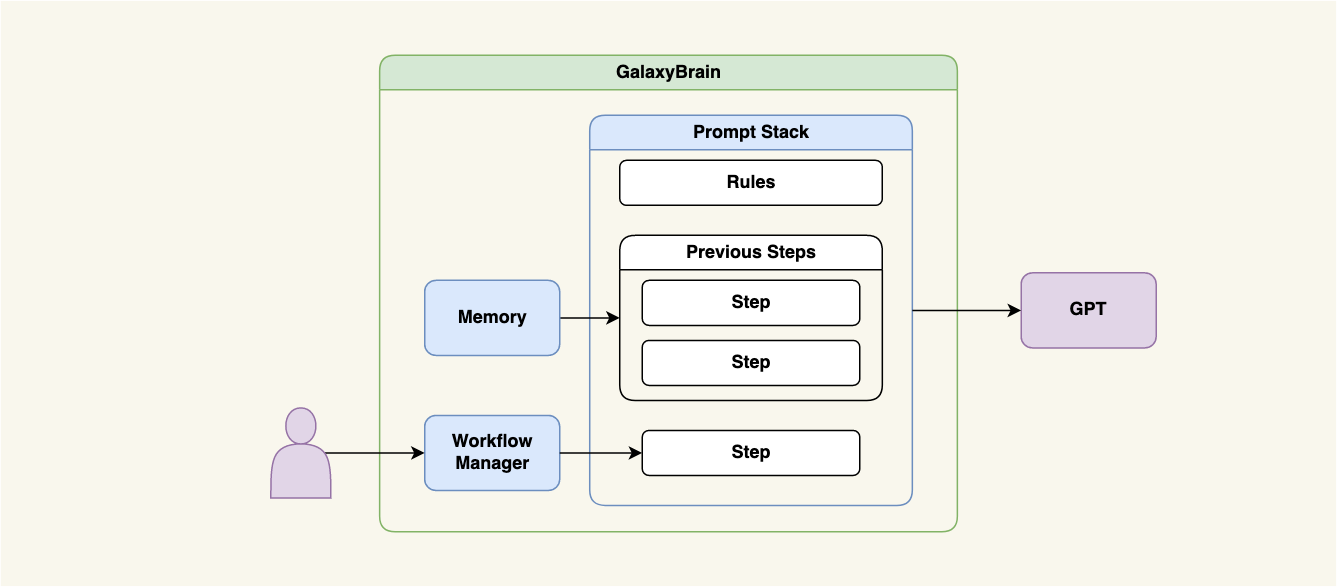 Figure 1. Unbounded and buffer memory architecture.
Figure 1. Unbounded and buffer memory architecture.
3. Summary Memory
Summary memory introduces a new abstraction called a summarizer. After we receive a response from the model, we can progressively summarize the first max(0, len(all_steps) - offset) steps of the workflow in a separate call and keep the rest of them unsummarized. This type of memory can support very long workflows, but it reduces memory fidelity as more and more steps are compressed in the summary blob. We could use GPT-3 or some other language model API to generate summaries. However, text summarization is a pretty broad topic and there are other summarization methods available: Sumy, NLTK, and T5 among others. Here is a high-level diagram of how summary memory works:
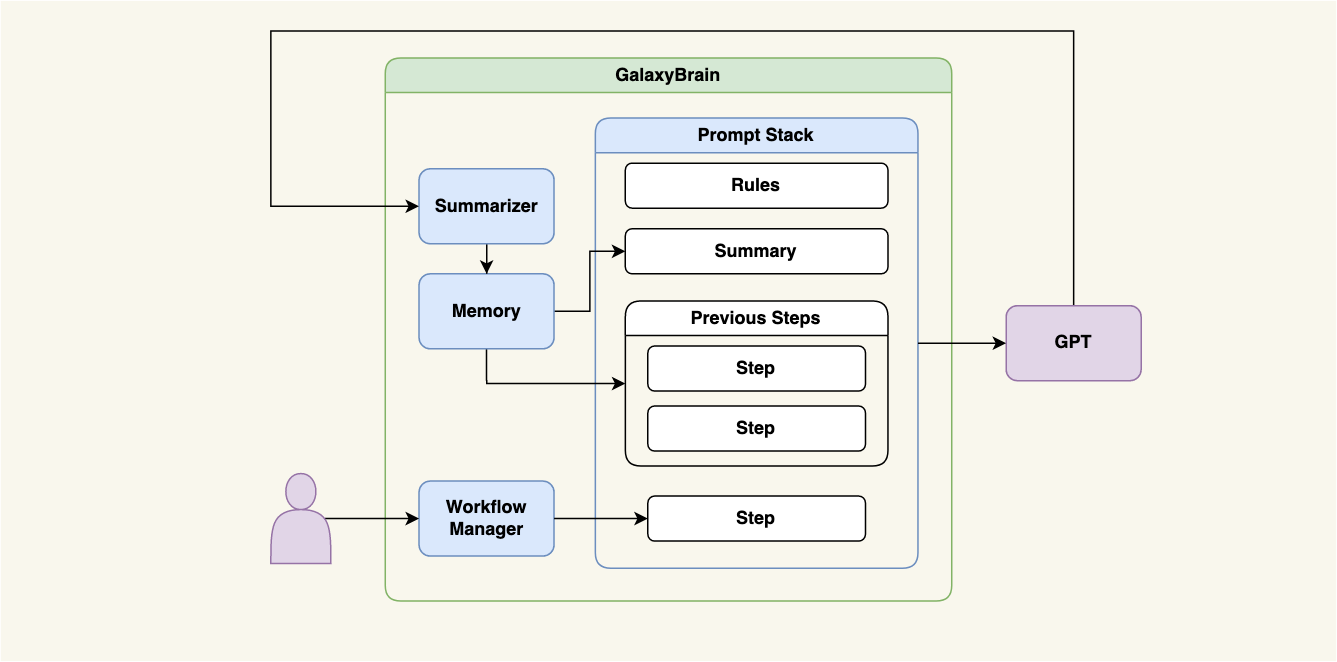 Figure 2. Summary memory architecture.
Figure 2. Summary memory architecture.
Now, let’s see how some of those methods can be accessed in GalaxyBrain.
Adding Memory to GPT
By default, GalaxyBrain uses unbounded memory called Memory. We don’t need to explicitly define it:
chat_rules = [
rules.meta.your_name_is("GalaxyGPT")
]
workflow = Workflow(
rules=chat_rules,
completion_driver=OpenAiCompletionDriver()
)
workflow.add_steps(
CompletionStep(input=Prompt("Hey, I'm Vasily. How are you?")),
CompletionStep(input=Prompt("Tell me about yourself.")),
CompletionStep(input=Prompt("Who are you talking to?"))
)
workflow.start()
Here is what the conversation part of the prompt looks like after processing the first three steps:
Conversation begins:
Q: Hey, I’m Vasily. How are you?
A: Hi Vasily, I’m GalaxyGPT. I’m doing well, how about you?Q: Tell me about yourself.
A: I’m GalaxyGPT, a chatbot that is designed to answer questions and provide information. I’m powered by artificial intelligence and I’m constantly learning new things. I’m here to help you with any questions you may have.Q: Who are you talking to?
A: I’m currently talking to you, Vasily.
Now let’s use BufferMemory with the buffer size of 1, meaning that we only pass one preceding step in addition to the current step:
workflow = Workflow(
rules=chat_rules,
completion_driver=OpenAiCompletionDriver(),
memory=BufferMemory(buffer_size=1)
)
The result, as expected, is quite different:
Conversation begins:
Q: Tell me about yourself.
A: I’m GalaxyGPT, a chatbot that is designed to answer questions and provide information. I’m powered by artificial intelligence and I’m constantly learning new things. I’m here to help you with any questions you may have.Q: Who are you talking to?
A: I’m not sure what your name is, but I’m happy to help you find out.
Finally, let’s try using SummaryMemory:
driver = OpenAiCompletionDriver()
workflow = Workflow(
rules=chat_rules,
completion_driver=driver,
memory=SummaryMemory(
summarizer=CompletionDriverSummarizer(driver=driver),
offset=0
)
)
Here we set the offset to 0, which means that we progressively summarize every response that the model returns to us:
Summary of the conversation so far:
Vasily introduced himself and GalaxyGPT responded by introducing itself as a chatbot powered by artificial intelligence, ready to help with any questions.
Conversation begins:
Q: Who are you talking to?
A: I’m currently talking to Vasily.
To leave some steps unsummarized, simply increase the offset.
Implementing a Mini Version of ChatGPT
Now, let’s do something fun! I’m going to use GalaxyBrain and Gradio to implement a basic version of ChatGPT in just 40 lines of code:
# Define a few basic rules for the workflow.
chat_rules = [
rules.meta.speculate(),
rules.meta.your_name_is("GalaxyGPT")
]
# We'll use SummaryMemory in order to support very long conversations.
driver = OpenAiCompletionDriver(temperature=0.5, user="demo")
memory = SummaryMemory(summarizer=CompletionDriverSummarizer(driver=driver))
workflow = Workflow(rules=chat_rules, completion_driver=driver, memory=memory)
# Gradio magic begins!
with gr.Blocks() as demo:
def conversation_history() -> str:
return workflow.memory.to_conversation_string()
def conversation_summary() -> str:
return workflow.memory.summary
# This is where we add new steps to the workflow and "resume" it on
# every received question.
def ask_question(question: str) -> Tuple[str, str]:
workflow.add_step(
CompletionStep(input=Prompt(question))
)
workflow.resume()
# Here we return full conversation history and conversation summary.
# We output both to demonstrate how the summary changes with every asked
# question.
return conversation_history(), conversation_summary()
# Finally, let's setup a UI with Gradio primitives.
gr.Markdown("# GalaxyGPT")
with gr.Row():
with gr.Column():
user_input = gr.components.Textbox(label="Your Input")
translate_btn = gr.Button(value="Submit")
with gr.Column():
output = gr.Textbox(label="Conversation History", value=conversation_history)
summary = gr.Textbox(label="Conversation Summary", value=conversation_summary)
translate_btn.click(ask_question, inputs=user_input, outputs=[output, summary])
demo.launch()
Here is what it looks like in action after I asked several questions about quantum mechanics:
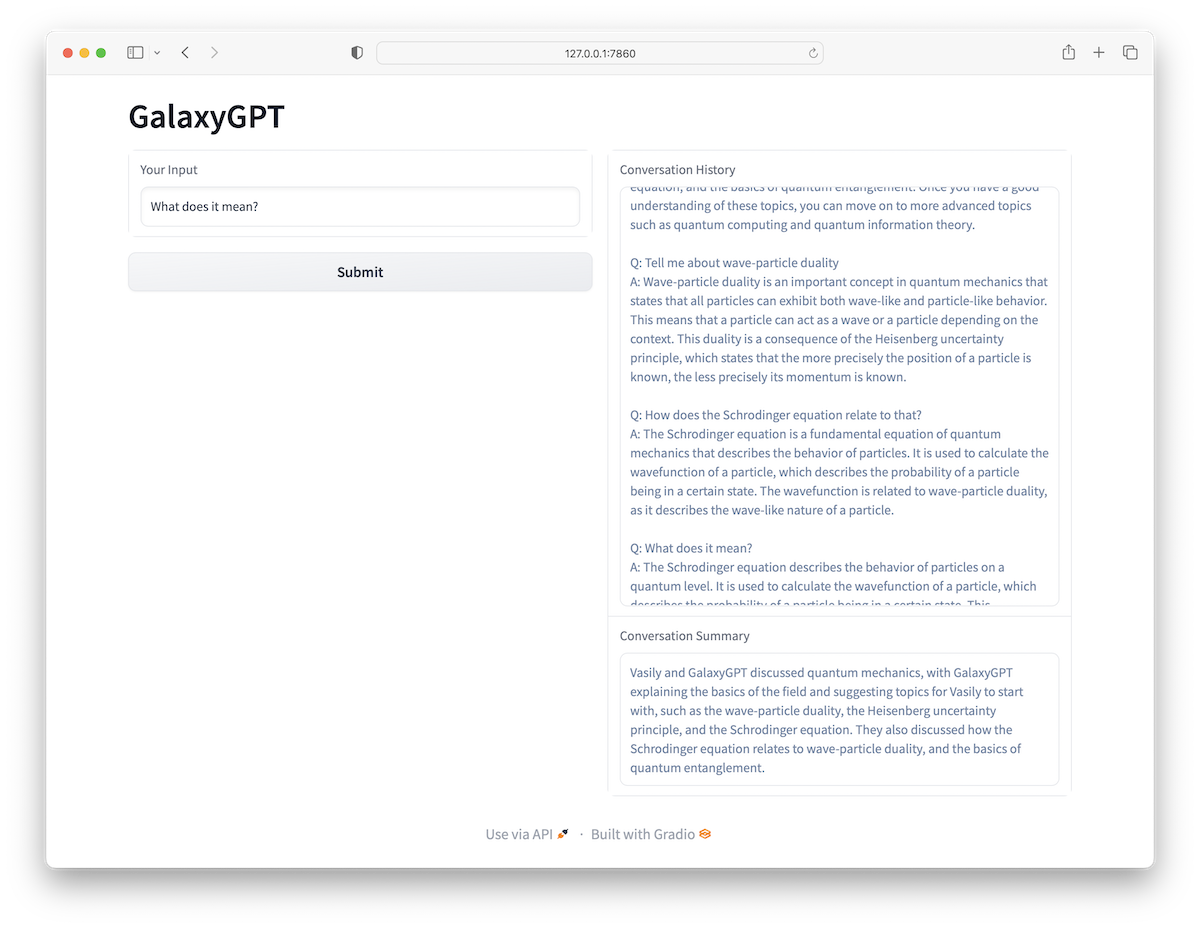 Mini version of ChatGPT build with GalaxyBrain.
Mini version of ChatGPT build with GalaxyBrain.
That’s a wrap!