Is It Web 3.0 Yet?
Note from the future: this article is not about web3! It’s about the Semantic Web. Please update your priors accordingly 😁
Is it Web 3.0 yet? Do not know what Web 3.0 is exactly? Well, this article is a gentle introduction into the future of the web that is being discussed by some but never has been exposed to the greater public. Get ready to learn something completely new which will become dominant on the web in the next several years.
Introduction
Web 2.0 is usually associated with web applications that involve interactive information creation and sharing, user-based ratings, and massive collaboration. Web 2.0 may sound like a new version of the web, but it is, in fact, not an update of any current technologies or specifications; rather, it is a change in the way web developers and end-users use the Web. The term “Web 2.0” was first mentioned in 1999 by Darcy DiNucci. She wrote the following in her article:
The Web we know now, which loads into a browser window in essentially static screenfulls, is only an embryo of the Web to come. The first glimmerings of Web 2.0 are beginning to appear, and we are just starting to see how that embryo might develop. The Web will be understood not as screenfulls of text and graphics but as a transport mechanism, the ether through which interactivity happens. It will still appear on your computer screen, transformed by the video and other dynamic media made possible by the speedy connection technologies now coming down the pike. It will also appear, in different guises, on your TV set (interactive content woven seamlessly into programming and commercials), your car dashboard (maps, yellow pages, and other traveler info), your cell phone (news, stock quotes, flight info), hand-held game machines (linking players with competitors over the Net), maybe even your microwave oven.
Web 2.0 sites allow users to not only retrieve information, but to also run applications directly through a browser. All the data that users own can be shared, rated, and embedded by others. Participation became a very important part of the Web 2.0 experience, in contrast to Web 1.0. The way information is saved on servers and in databases did not really change. Relational databases still hold most of the data that is shown to users. These databases are usually related to some particular service and are stored and shared within one organization.
 Tag clouds are one of the signature features of Web 2.0. This particular one represents concepts and technologies that are related to Web 2.0 itself.
Tag clouds are one of the signature features of Web 2.0. This particular one represents concepts and technologies that are related to Web 2.0 itself.
Web 3.0, also known as the semantic web, is an evolving development of the web in which the meaning of information is defined for both humans and computers. Web 3.0 comprises a set of design principles, new technologies, and new ways to store information. It is the second wave of technological change on the web that may prove to be the most significant and disruptive yet to the old web. One of the most important technologies associated with Web 3.0 is cloud computing—a paradigm shift in which details are abstracted from users who don’t need to know any more about the infrastructure of the service they are using at any particular moment. A typical cloud computing service is an online application that is accessed from a browser and all data is stored on the servers that are not owned by the service creators. The services that are distributed between multiple computers only use the resources that they need. There is a good blog post on TechCrunchIT that argues for a paradigm shift towards Web 3.0 and cloud computing:
Web 3.0 changes all of this by completely disrupting the technology and economics of the traditional software industry. The new rallying cry of Web 3.0 is that anyone can innovate, anywhere. Code is written, collaborated on, debugged, tested, deployed, and run in the cloud. When innovation is untethered from the time and capital constraints of infrastructure, it can truly flourish.
This is a bold statement simply because it describes an entirely new concept that was not even possible to discuss until now.
Cloud Computing
The whole point of Web 3.0 is to make information accessible to people and computers at any time from any location. That’s why cloud computing seems to be such a great idea. If one computer or server breaks it doesn’t mean that the entire system goes down, it only means that a small piece of it doesn’t work, which is not harmful to the system as a whole. Users would still be able to access information and change it.
 This popular diagram shows the main idea behind cloud computing—all devices get hooked up to the cloud, which has needed information and services.
This popular diagram shows the main idea behind cloud computing—all devices get hooked up to the cloud, which has needed information and services.
In the paper Above the Clouds, Armbrust, Fox, and others argue that the time for cloud computing has finally come. They discuss different types of cloud computing and argue about its hardware aspect. Armbrust et al. believe that the key enabler of cloud computing is the construction and operation of extremely large-scale datacenters; these datacenters should be held at low-cost locations where fees for electricity and network bandwidth are significantly lower. This kind of cheap cloud is called a public cloud, and it is usually made available in a pay-as-you-go manner. The authors explain what an average application that uses cloud computing needs:
Any application needs a model of computation, a model of storage, and a model of communication. The statistical multiplexing necessary to achieve elasticity and the illusion of in?nite capacity requires each of these resources to be virtualized to hide the implementation of how they are multiplexed and shared. Our view is that different utility computing offerings will be distinguished based on the level of abstraction presented to the programmer and the level of management of the resources.
After this quick insight into the technological bases for Web 3.0, let’s look at different ways information can be presented to both humans and computers. This is a crucial part of the semantic web.
Semantic Web
To represent information on the web, html is widely used. However, it does have some limitations. html is not able to semantically connect pieces of information within itself. For example, one may create a list of employees on a webpage. The html of this page can make simple, document-level assertions like “This is a list of employees.” There isn’t any capability within the actual code, however, to assert unambiguously that employee with the id “2335” works in the sales department. Therefore there is no way to add connections between pieces of information that are present on a page.
“Semantics is the study of meaning, usually in language. The word “semantics” itself denotes a range of ideas, from the popular to the highly technical.” — Wikipedia
A solution to this problem within html is to add semantic value to html elements, which is currently being implemented in the latest (fifth) version of html. For example, using an tag denotes “emphasis” in places where it’s needed (this works in all versions of html). Another way is to use microformats, which are unofficial attempts to extend html syntax by adding specific classes and relative attributes to html elements. Microformats create machine-readable semantic markup about objects like persons, events, or feeds of information.
In Web 3.0, adding semantic value to elements and using microformats is extended further. It involves publishing information specifically designed for data. Examples of such languages are Resource Description Framework (rdf), Web Ontology Language, and xml. These new descriptive languages can describe arbitrary things like events, structures, and news. They also allow interlinked connections to be created between all sorts of data, which helps aggregators and crawlers to navigate in the huge information graph which represents the Internet. The content is displayed as descriptive data and is stored in relational databases that use cloud computing.
Twitter is a social micro-blogging service that enables users to send and read short messages. It began as a service for groups of friends and relatives to “follow” each other and share what happened to them during the day. Now it has grown into something much bigger, and is called the bridge to Web 3.0 by some. When people use Twitter today, they don’t necessarily follow their friends or relatives. Instead, they follow people anywhere in the world that share the same ideas or interests. People posting about similar things can easily be found by using tags on information. If somebody is interested in dogs, she can search for information tagged as #dogs and find current, active discussions about dogs on Twitter in real time.
The simple model suggested by Twitter reflects the fact that describing separate small chunks of information by tagging works well. People can easily manage it, as well as computers that crawl and syndicate text information. This principle can readily be applied to other types of information such as videos, images, people’s profiles, articles, and news.
The beauty of Twitter is in its coherent api that can be accessed via xml—one of the descriptive languages that represents information semantically. Simply speaking, it is a set of rules for encoding information electronically. There are a variety of programming interfaces which developers can use to access xml data from Twitter and make it acceptable in any software product, web service, or site.
 When Twitter experiences an outage, users see the “fail whale” error message image, created by Yiying Lu. It has become iconic and adored by Twitter users.
When Twitter experiences an outage, users see the “fail whale” error message image, created by Yiying Lu. It has become iconic and adored by Twitter users.
Cloud computing was able to solve outage problems that Twitter used to experience. There is a record of Twitter being up for 98% of the time in 2007, which is a high percentage for a service used by millions of people daily. Still, there are a number of possible problems and challenges that cloud computing and semantic web face (which are two components of Twitter). Security is one of the greatest problems. On July, 16, 2009, CNN reported on hacking into Twitter systems. They investigated whether cloud computing, which holds a user’s data in multiple locations, is secure enough:
The recent hacking of a Twitter employee’s personal e-mail account is raising questions about the security of storing personal information and business data on the Internet. The Web has been buzzing since a hacker allegedly broke into a Twitter administrator’s personal e-mail account about a month ago and used that information to access the employee’s Google Apps account.… The hacker sent 310 documents to the tech site, according to a post by Michael Arrington, TechCrunch’s founder and co-editor.… In what appears to be a separate incident, a hacker broke into Twitter chief executive Evan Williams’ wife’s e-mail account and then accessed Williams’ PayPal and Amazon accounts, Twitter says.… It’s unclear what if any impact the incidents will have on the future of cloud computing, the idea that documents and computing power can be stored “in the cloud” of the Internet rather than on desktops or laptops.
Web 3.0 Challenges
Web 3.0 assumes that computers will be using their own reasoning to deal with tons of information, available in forms like rdf, xml, or any other markup language. To catalog information in real time and deal with its vagueness, systems will have to use fuzzy logic in order to process different types of information.
Uncertainty and inconsistency are the two other big challenges that developers of Web 3.0 face. Uncertainty refers to something a system can’t easily classify and save to the appropriate table in the database. Inconsistency stands for logical contradictions which inevitably arise during the development of large systems. One can’t use deductive reasoning to solve this problem. Instead, defeasible reasoning and paraconsistent reasoning should be used. Defeasible reasoning is a kind of non-demonstrative reasoning, where the actual reasoning does not produce a full or final demonstration of the relation between semantic elements. Paraconsistent reasoning involves contradictions that may arise in a discriminating way, which provides a simple and intuitive formal account of truth in semantics.
Other problems associated with Web 3.0 expansion are the vastness of the web and security issues with cloud computing. According to WorldWideWebSize.com, the web today contains at least 20 billion indexed pages. This is a rather big input for any modern system that deals with information and semantics. It will take some time to remove all duplicate terms and to outline information with semantic values that are specific to the subject.
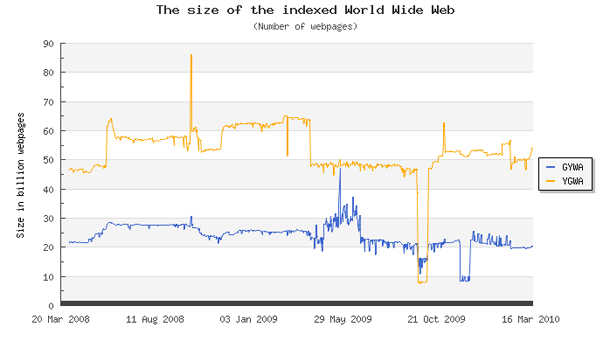 GYWA results are being sorted by Google, Yahoo!, Bing, and Ask and ygwa results by Yahoo!, Google, Bing and Ask. This means that Google has most of the indexed pages on its servers.
GYWA results are being sorted by Google, Yahoo!, Bing, and Ask and ygwa results by Yahoo!, Google, Bing and Ask. This means that Google has most of the indexed pages on its servers.
Cloud computing faces multiple security and privacy issues these days. Since information is being stored on multiple servers, it is hard to control and to provide a high level of security in all places and on all levels. One of the recent articles in Communications of the ACM magazine discusses major topics in cloud computing:
Finally, cloud computing raises questions about privacy, security, and reliability—a major subject of discussion at a workshop held last January at the Center for Information Technology Policy at Princeton University. Allowing a third-party service to take custody of personal documents raises awkward questions about control and ownership: If you move to a competing service provider, can you take your data with you? Could you lose access to your documents if you fail to pay your bill? Do you have the power to expunge documents that are no longer wanted?
Developers have been trying to solve security issues for a while. Today, we can tell that some were successfully resolved. Many of the big players in the computer world today such as Google, Mozilla, and Microsoft have started using and promoting cloud computing as a service that everybody can use.
Summary and Conclusion
The Web 2.0 to Web 3.0 migration has had a successful start; now users and businesses can consider it as a serious platform for creating and publishing information. A number of apis have been developed for laying out information semantically, so that information that is stored in relational databases can be adequately processed by both humans and computers. As a technological basis, cloud computing will be used intensively, so that resources will not need to be stored on one server that can in theory go down any time.
There are still quite a few challenges that Web 3.0 developers are faced with, yet they are being resolved slowly but surely. Twitter has set a successful example already by combining the latest information on the web into a real-time feed of tweets. The future of the web is Web 3.0. This will eventually lead to tagging all online information, creating links between related pieces that will be fully understood by humans and computers.